1. NUMA란?
NUMA는 메모리를 관리하는 방법 중 하나이다.
가장 기본적으로 메모리를 관리하는 방법은 하나의 512GB 메모리에 대해서 여러 CPU가 선점유 방식을 통해 접근하는 방법이 있다.
예를 들어 4개의 CPU core가 존재한다고 가정했을 때 하나의 CPU가 메모리에 접근하여 사용 중에 있다면 남은 3개의 core는 메모리에 접근할 수 없고 대기해야하는 병목현상 문제가 발생하게 된다.
이 때, 이를 보다 효율적으로 해결하기 위해 생겨난 방법이 NUMA 메모리 관리 기법이다.
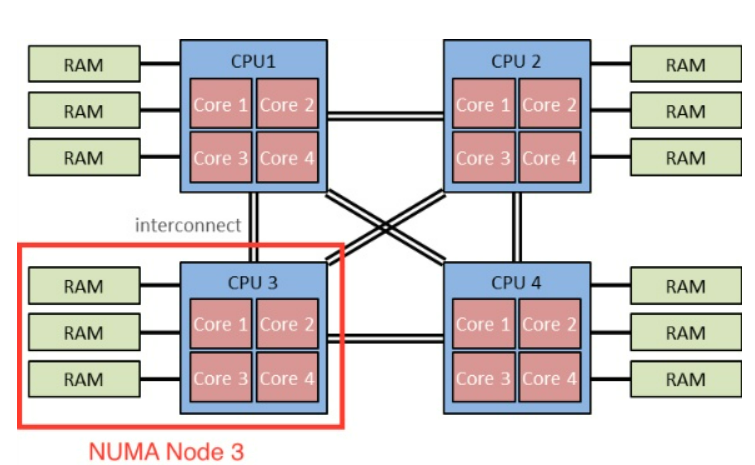
NUMA 노드의 경우 위와 같이 메모리를 주소별 구간으로 나눈 뒤 각각의 CPU에 할당하는 방식이다. 예를들어 512GB 메모리가 존재한다면
0~128까지는 CPU1
128~256 -> CPU2
256~384 -> CPU3
384~512 -> CPU4
로 CPU별로 접근하는 메모리를 나누어서 진행한다. 이 경우 하나의 메모리라도 구간이 나누어져있기 때문에(H/W, S/W적으로 나눌 수 있음) 각 메모리 구간에 대하여 동시에 접근이 가능하다. 즉 병목현상 문제를 해결할 수 있다.
2. 성능
NUMA는 위와 같이 core별로 메모리 area를 정하고 가능한 해당 메모리만을 사용하도록 하여 병목현상을 해결하는 장점을 가지고 있다.
하지만 OS 동작 중에 현재 core에서 가지고 있지 않은 메모리 주소에 접근이 필요한 경우가 존재할 것이다.
예를 들어
0x00~0x25 core 1
0x25~0x50 core 2
라고 했을 때 core1에서 0x40에 접근이 필요하게 된다면 NUMA 구조상 문제가 발생할 수 있다.
이 때는 core1이 0x40에 접근하는 방식을 remote라고 하며 remote를 하는 경우 예기치 못한 시간소요가 발생하게 된다.
때문에 NUMA를 지원하는 모델을 구현하기 위해서는 예기치 못한 remote가 얼마나 일어나는지 빈도수를 계산해서 memory area를 정해야 한다.
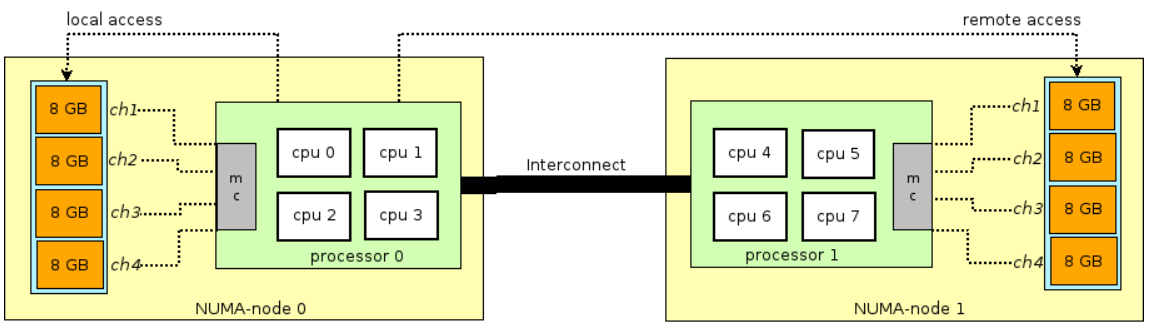
그림으로 다시 한 번 정리하면 NUMA의 경우 실제적으로 cpu(core) n개를 하나의 NUMA node로 묶어서 사용한다. NUMA node내에서 접근을 local access라고하며 각각의 NUMA node에서 각각의 local access는 동시에 일어날 수 있고 이를 바탕으로 병목현상 문제에 강한 면모를 보일 수 있다.
하지만 앞서 말한내용과 같이 NUMA의 성능에서 중요한 포인트는 remote access이다. Remote access는 local memory allocate등의 동작을 진행할 때 문제가 발생하면 remote access가 발생하고 현재 cpu가 존재하는 NUMA node가 아닌 다른 NUMA node에서 작업을 처리하게 된다. 이 때 발생하는 시간적인 소요가 15%정도 나는 것으로 보이며 결과적으로 NUMA model을 optimization하기 위해서는 어떻게 NUMA node를 설계해서 remote access를 최소화 하는지가 관건이다.
- Ref
https://cheonee.tistory.com/entry/Automatic-NUMA-Baleancing%E3%85%87%E3%85%87?category=537099
https://www.boost.org/doc/libs/1_66_0/libs/fiber/doc/html/fiber/numa.html
'OS > Linux' 카테고리의 다른 글
| [Linux Kernel] Kernel 분석(v5.14.16) - Memory Zone & Sparse (0) | 2022.02.13 |
|---|---|
| [Linux Kernel] Kernel 분석(v5.14.16) - Memory Model (0) | 2022.02.01 |
| [Linux Kernel] Kernel 분석(v5.14.16) - memblock (0) | 2022.01.23 |
| [Linux Kernel] Kernel 분석(v5.14.16) - I/O mapping (0) | 2021.12.26 |
| [Linux Kernel] Kernel 분석(v5.14.16) - Page Table (2) (0) | 2021.12.12 |